

Creating an XDS Policy with performance in mind
Part 4 - Getting data; Can you SELECT() something faster?
What does adding a Select() do?
One ability that OData offers is the ability to reduce the result set for the request using a Select() command. This can reduce the number of columns in a result set from 100 to just 5. This can be used to provide only required data for a given request. However, does this really work as expected from a performance perspective? So far we have focused on SQL and application level performance. However, this can be used to address network / latency issues between where Finance and Operations is vs where the app consuming the OData endpoints. This can be use to reduce the overall amount of data that the integrated app is asking for. Consider an app asking for 100 columns at an average of 8kb per column vs 5 columns at the same average. That's 800kb vs just 40. There are a lot of infrastructure questions that need to be answered for if such a distinction is important. Overall, let's not be wasteful with "over-the-wire" traffic whenever we can. But is this getting all fields then applying filter to only bring back the requested columns or is this only getting those columns requested from the start? Let's find out. All code for all data presented here can be found at https://github.com/NathanClouseAX/AAXDataEntityPerfTest.
The Setup
We'll have the same set of entities and tests as we did in part 3 but this time we're running the same tests with a Select() statement in an additional set of tests. We will also be running the tests in a VHD-to-VHD setting as well as Tier1-to-Tier1 and finally VHD-to-Tier1. Each test on each entity was performed with all fields presented for the given data entity then another set of tests were run where we are selecting 5 fields that all entities have in common. This is an example of how to use a Select():
context.SalesOrderHeaderV2ExistAddrReadOnlys.Where(x => x.dataAreaId == DataAreaId && x.OrderingCustomerAccountNumber == customerAccount)
.Select(x => new { x.SalesOrderNumber, x.OrderingCustomerAccountNumber, x.InvoiceCustomerAccountNumber, x.SalesOrderStatus, x.dataAreaId })
.Take(count)
.ToList();
Key Takeaways
We're going to have the summary be first because doing a deep dive doesn't provide a lot more than this initial screenshot.
- Using a Select() will provide some performance improvements when fetching more than 1 record
- Using a Select() will provide some performance degradation when fetching just 1 record
Let's take a look at the data in aggregate. These tests are across all data entities used in Part 3.
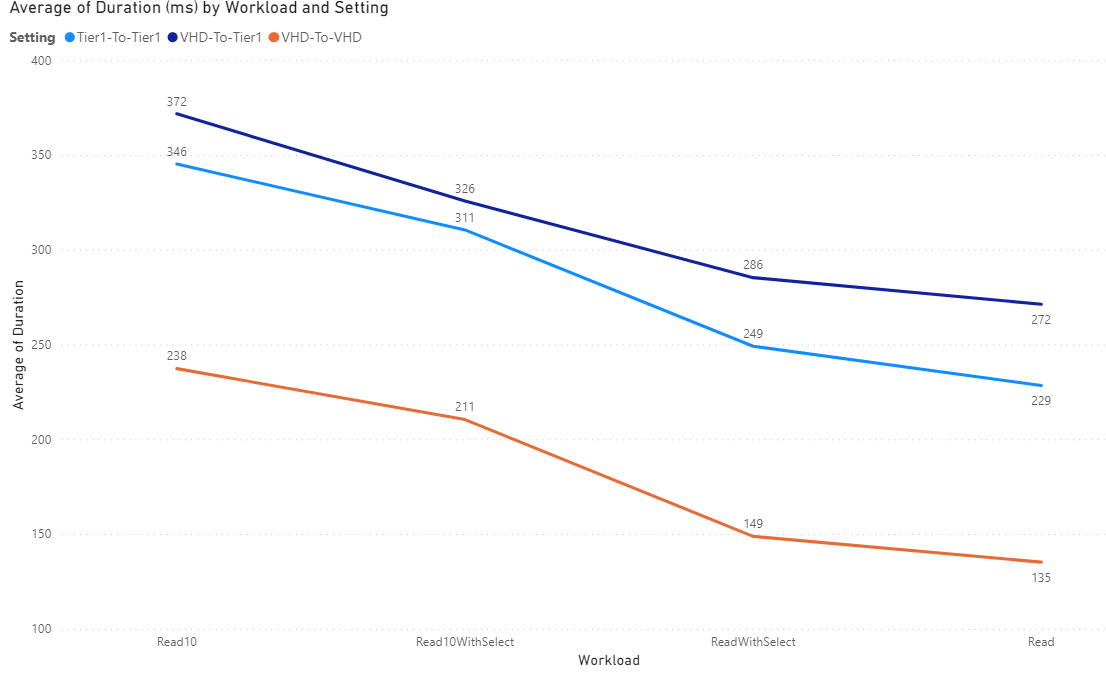
From left to right, you can see our slowest workload is a simple Read 10 where we are just reading 10 records. That makes sense. That looks like the most amount of work. Next is Read 10 with a Select(). We're getting approximately the same data but we're getting far fewer columns so that's less work for that workload which means better performance. This effect is specially pronounced when considering "over the internet" travel time for data. However, the next item that is the second fastest is Read with Select. In this, we are reading 1 record with a Select(). We can see the times are higher than just a simple read with no Select(). I would expect that getting 5 fields for 1 record is less work than getting 100 for that same record. However, it appears that just like with constructs related to OData, Data Entities and SQL, scale matters and there is some fixed percentage overhead when performing an operation. We see that overhead with a Read with Select() but its less visible when looking at a Read 10 With Select. The fastest is reading just 1 record with no Select().
Deep Dive Into Each Entity by Setting
AAXSalesTable
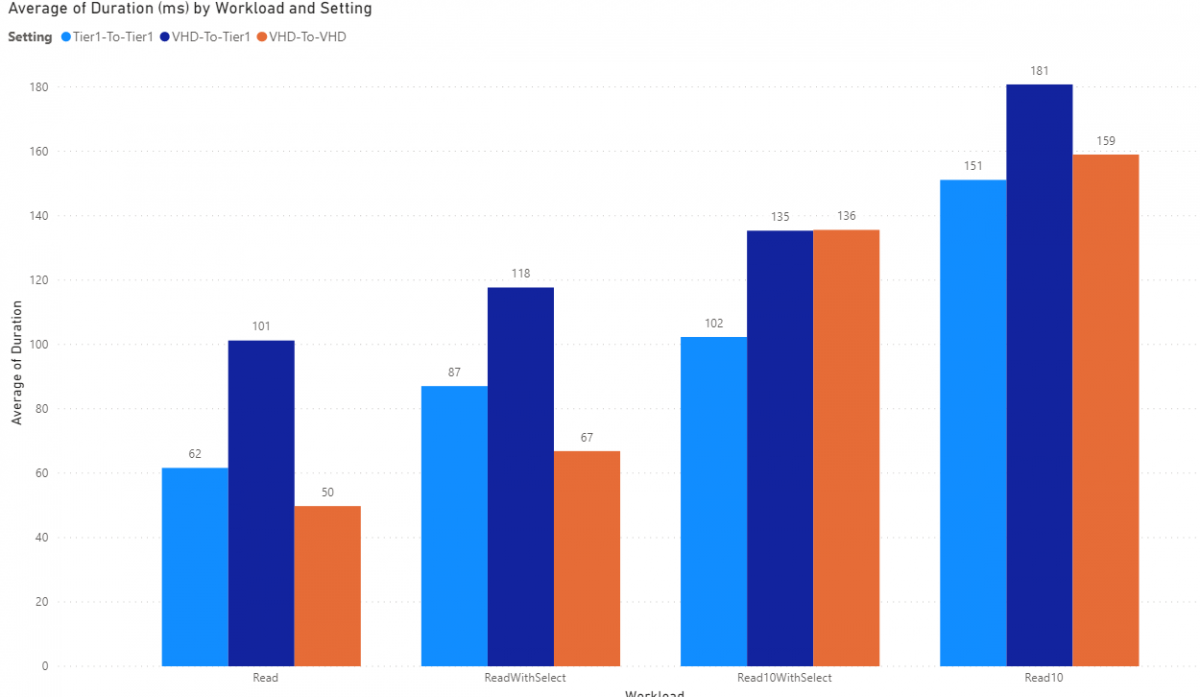
AAXSalesTableEntity presents with 174 columns and we are selecting only 5 for our tests. So using a select when reading 10 (or more) does improve performance, it's a huge performance increase.
AAXSalesTableEntityReadOnly
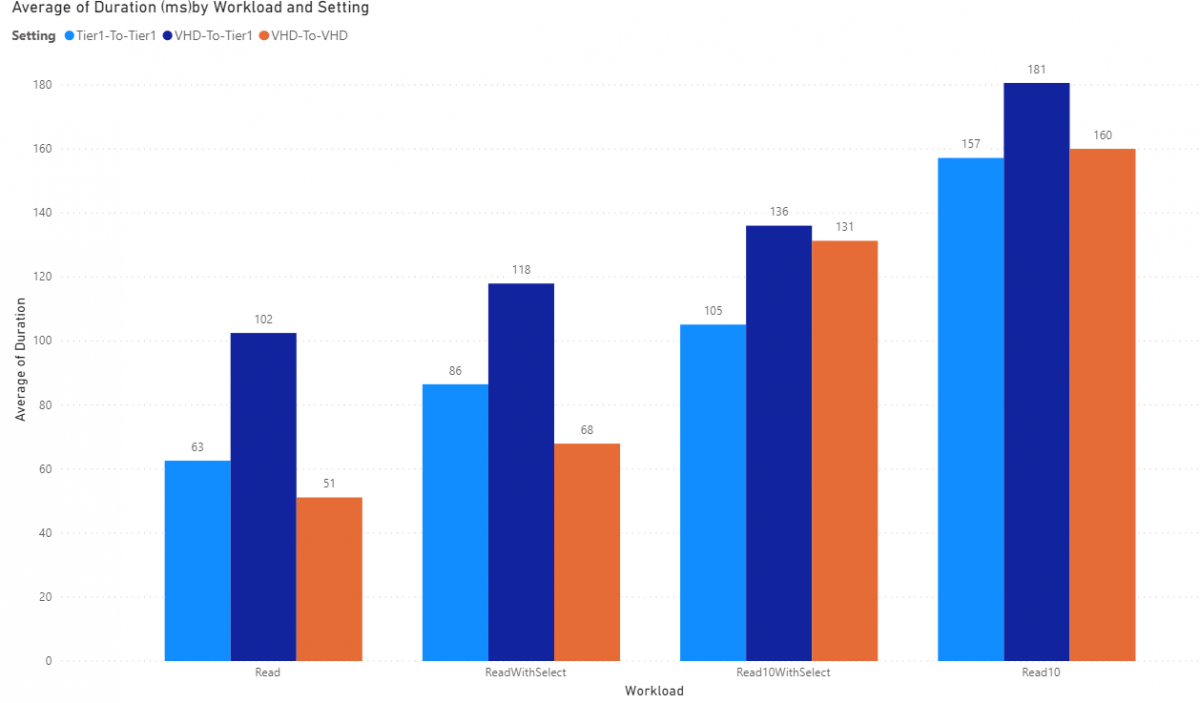
AAXSalesTableEntityReadyOnly also presents with 174 columns and we are selecting only 5 for our tests. Not much difference from the AAXSalestableEntity entity.
SalesOrderHeaderV2
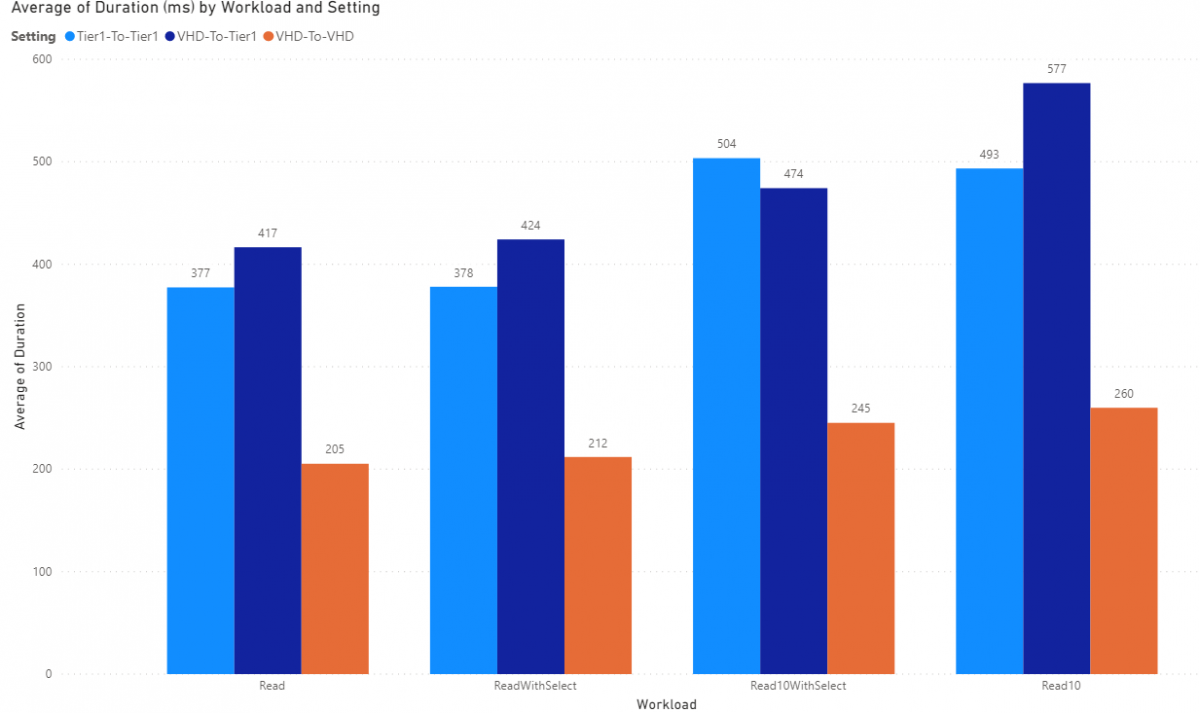
SalesOrderHeaderV2Entity presents with 250 fields and again we're only selecting 5. Not much to remark on other than the introduction of the VHD-to-Tier1 did perform better than the simple Read 10 so we can see the advantage of a Select() when considering network latency. This was from a home interent connection to a VM hosted in Central US Azure.
SalesOrderHeaderV2EntityDSReadOnly
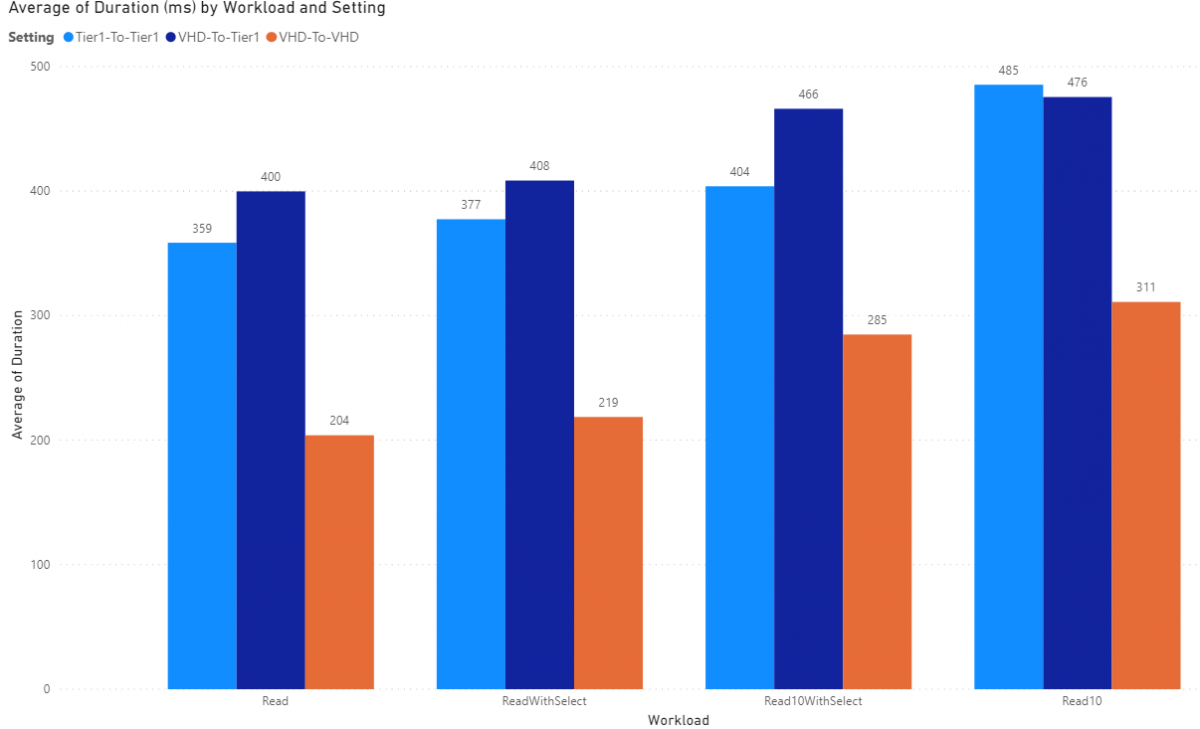
This presents with 244 columns. Similar to the last entity but the benefit of a Select() is far less pronounced and I'm not sure why.
SalesOrderHeaderV2EntityOnlySalesTable
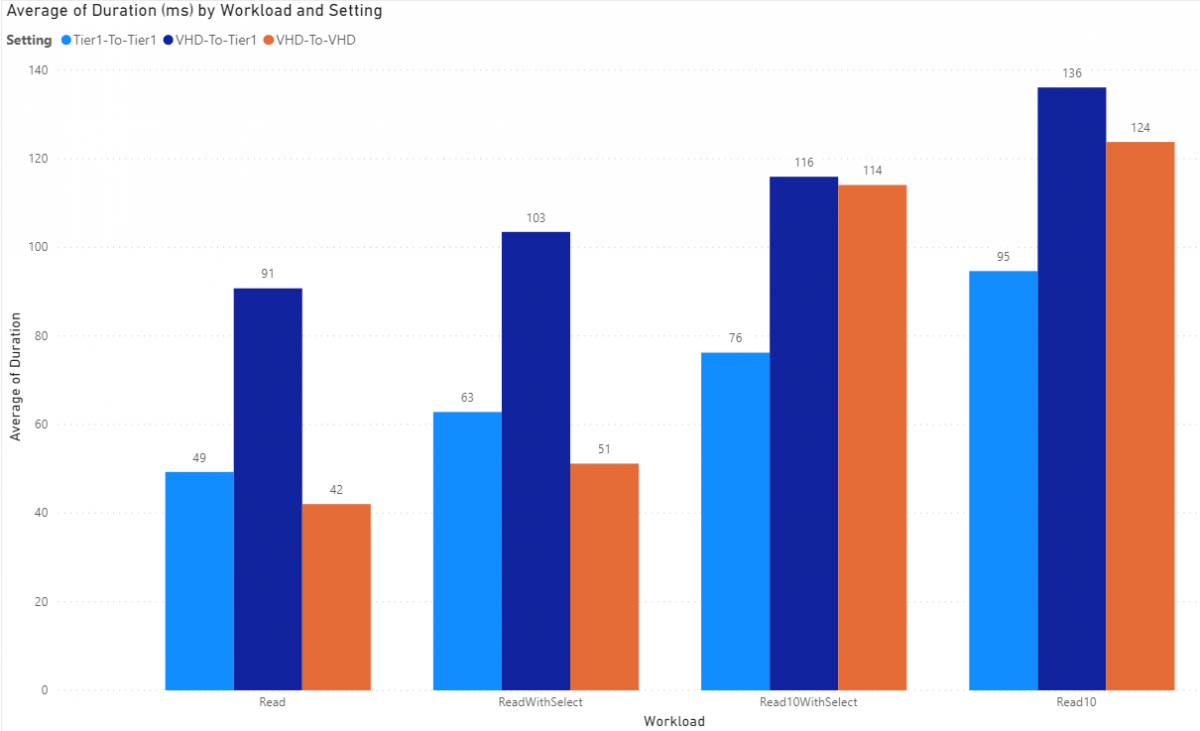
SalesOrderHeaderV2EntityOnlySalesTable presents with 87 columns and we're again only selecting 5. Overall a Select() does improve all a Read 10 workload.
SalesOrderHeaderV2EntityReadOnly
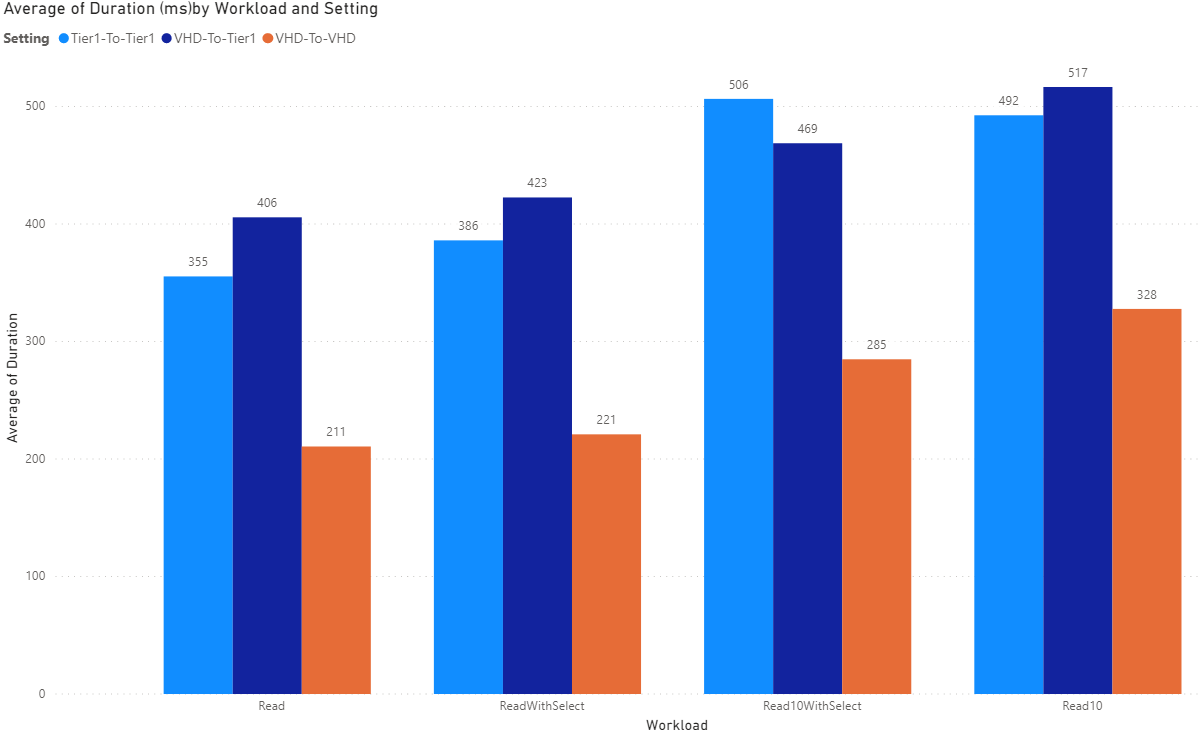
This presents with 244 columns. Similar to the last entity but the benefit of a Select() is far less pronounced and I'm not sure why. Could be some differences between SQL or stroage configurations.
SalesOrderHeaderV2EntityNoGlobalization
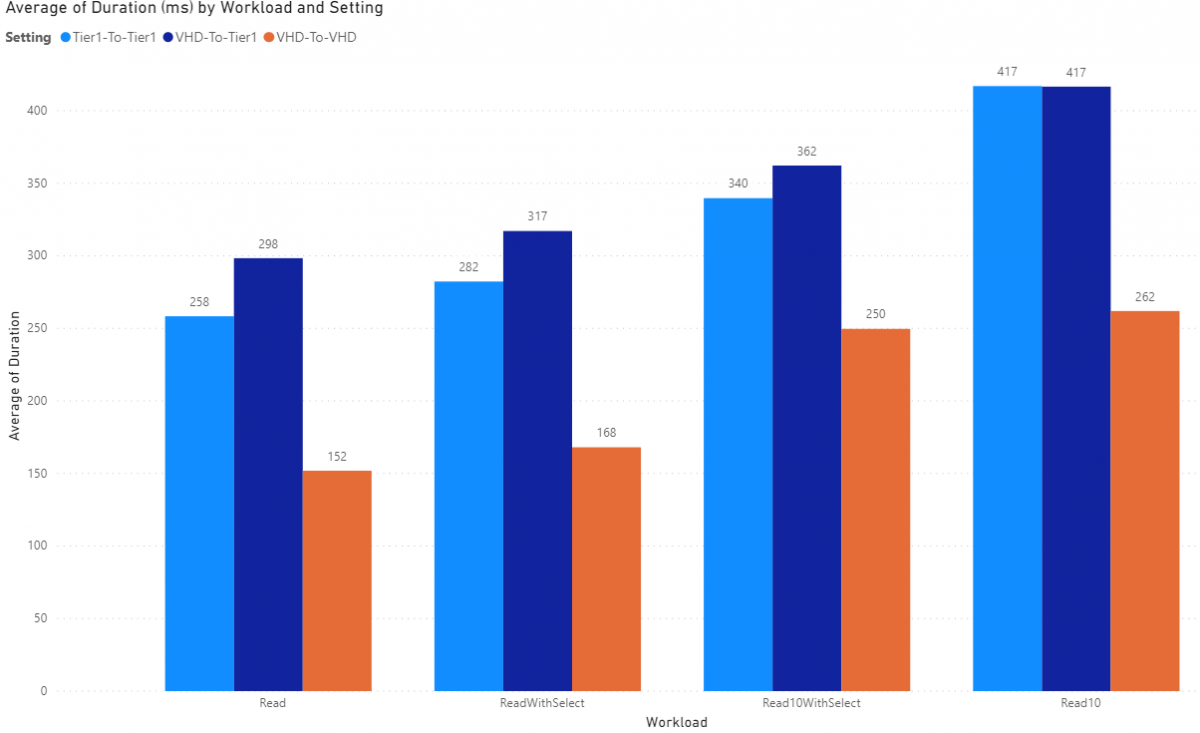
SalesOrderHeaderV2EntityNoGlobalization entity is presenting with 202 columns and again we're selecting only 5. Similar results as the others with the Read 10 workload for Tier1-To-Tier1 and VHD-To-Tier1 being identical which is interesting.
SalesOrderHeaderv2ExistAddrReadOnly

SalesOrderHeaderv2ExistAddrReadOnly entity presents with 183 columns and again we're selecting 5. Interesting results like the last entity.
All data and Power BI visuals can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest/tree/main/Projects/AAXDataEntityPerfTest/Part4/Analytics
All code can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest
Blog Main Tag:











