

Creating an XDS Policy with performance in mind
Part 5 - Getting Data and Indexes
Do Indexes matter when getting data via OData?
We're going to review what kind of performance we get when trying to fetch data from an OData entity. What I wanted to find out with this article was to what degree indexing on a table mattered for OData. For a read workload, all data entities are presented in the database by a view that is not schema bound. So, indexing always matter but to what degree does it matter? Let's take a look. All code presented here can be found at https://github.com/NathanClouseAX/AAXDataEntityPerfTest.
The Tests
Since we'll only be looking at indexing on one specific table, SalesTable, we can use an out of the box data entity to collect some data. We'll be using SalesOrderHeaderV2 for all tests. We'll be randomly requesting 100 records from that entity from each of the following (on table SalesTable):
- SalesId
- InventSiteId
- InventLocationId
- SalesName
Some indexes cover some of those fields while other do not. We'll also be testing fetching just 1 record and fetching 10 records as well as some testing against specific indexes to see if we can discern anything from that.
Fetching 1 Record
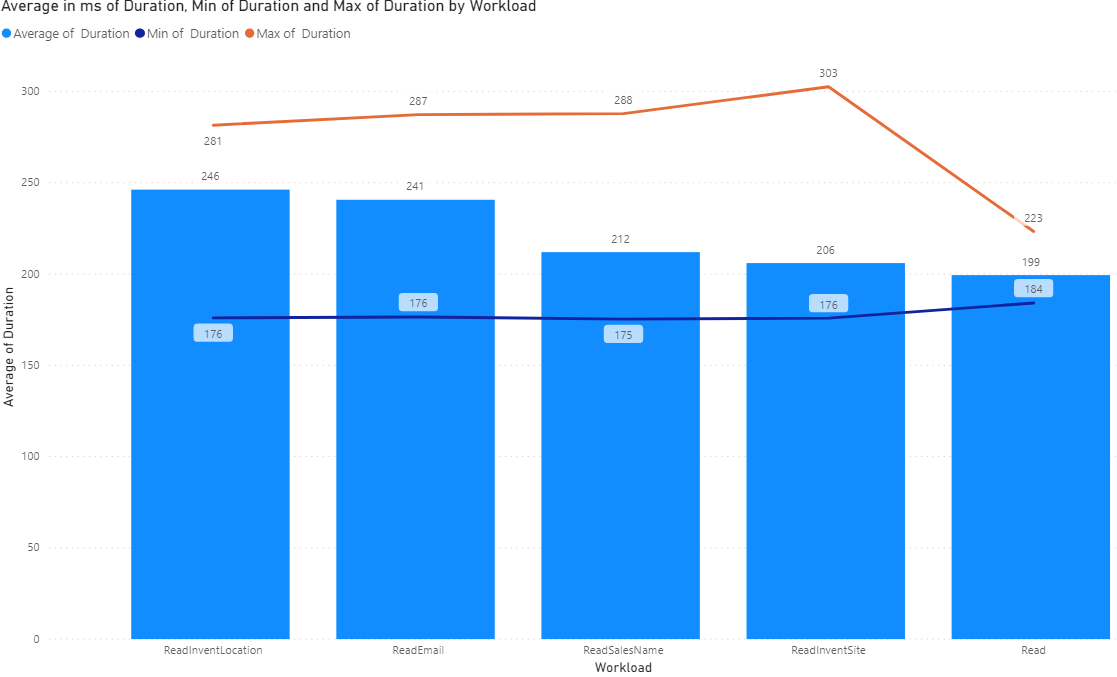
What we have here is our slowest performing lookups for 1 records from left to right. Our slowest lookup is against InventLocationId. That field isn't covered by any index so it makes sense that its not the fastest and if you look at the min and max duration values ( in ms ) you can see there is a fair amount of variability. This variability will increase as the sample data set size increased. I'm using Contoso data so if you had 250K Sales Order Headers, you would see even more variability. Next is Email. This field isn't covered by an index so its very similar to InventLocationId. The next field is SalesName. This one performing this well was a bit of a surprise but that's ok. It's probably more commentary on sample data size rather than anything else. This field is similar to InventLocationId. Next is field InventSiteId. This is similar to InventLocationId in that it's not covered by an index. Take notice of the variability so for testing, we may have just hit a cache several times and that could explain the favorable telemetry in aggregate. Next is just a standard read on SalesId. This is covered by 3 different indexes and as such, its our highest performing lookup and it has the least amount of variability between the min and max values for the fetch durations.
Fetching 10 Records
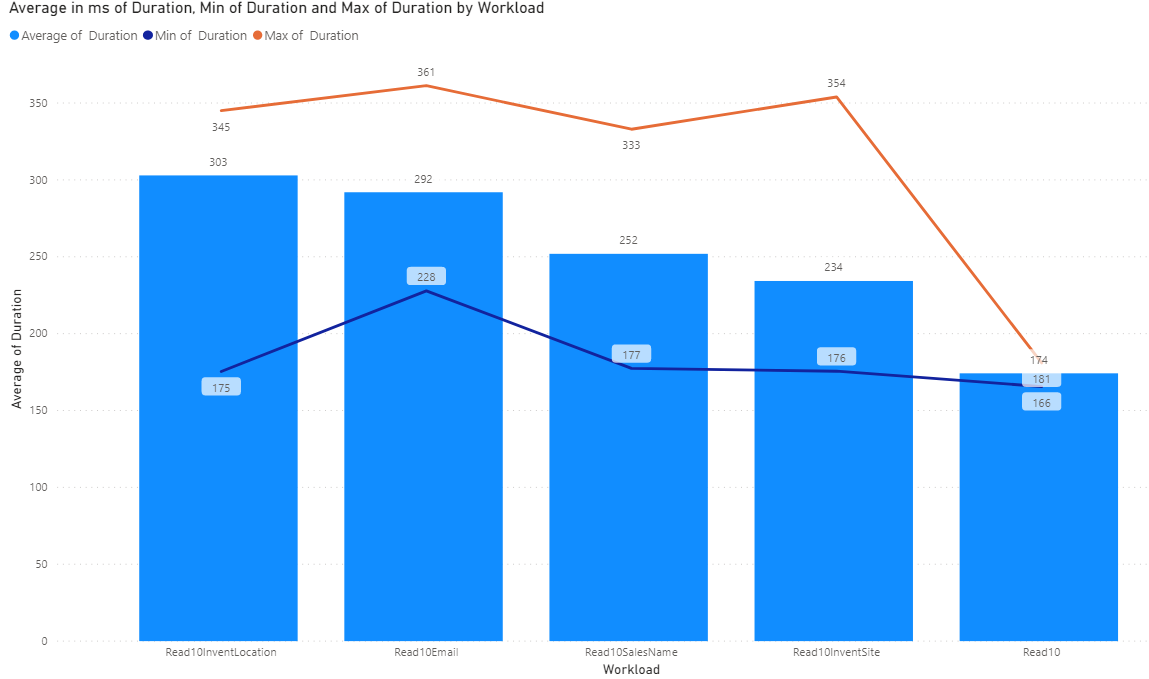
Here we're fetching at records that meet the given criteria. This is very similar to the last chart. However, it is highlighting that lookups based an index really do perform better than lookups not on an index. From left to right, we have our slowest to fastest lookups for 10 records and we are specifically querying on items that do have at least 10 records to be found for a given criteria. Our slowest is reading 10 records on InventLocationId, just like in the last graph. Next is Email then SalesName then InventSiteId just like the last graph. Our fastest with the least amount of variability is getting 10 Sales Orders by Ordering account. It's not really a surprise that when scaled up to 10 records from 1 record, our slowest to fastest lookups remained in the same positions.
Fetching 1 Record By Specific Indexes
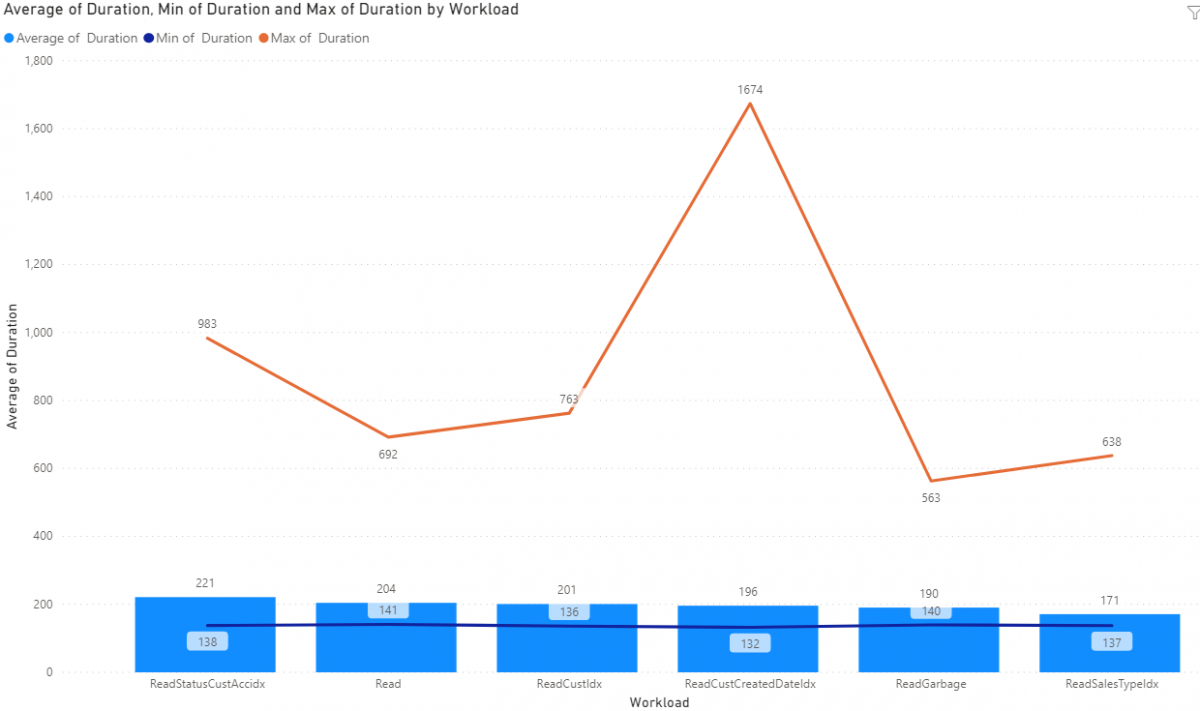
Next, we're going to see what index or lookup style is the fastest and if filter criteria overloading is something we need to worry about. We are lookup up 1 record at random by the field on a given index 100 times. We'll be looking at each item in the graph.
ReadCustCreatedDateIdx - We fetched records specific on fields DataAreaId, CustAccount and CreatedDateTime 100 times. This ended up being our worst performing index despiate the DateTime being part of the index. This also had the most variability so I suggest not using a DateTime based index for lookups. This index is not unique.
ReadStatusCustAccIdx - We fetched records on fields DataAreaId, SalesStatus and CustAccount 100 times. This was marginally better than the CustCreditDateIdx. This index is not unique.
Read - We fetched records on DataAreaId and SalesId. This is a standard random read on a Sales Order header. This index is unique so that is why it is so much faster than the CustCreatedDateIdx and StatusCustAccIdx.
ReadSalesTypeIdx - We fetched records on DataAreaId, SalesType and SalesId. Similar to the "read" test, we're looking up against a unique index but this index, SalesTypeIdx, is a subset of SalesId Index so its slightly more specific so it was marginally faster in our tests.
ReadGarbage - This was the wildcard in the test as we aren't hitting any specific index by design. We did 100 lookups based on all columns in all indexes included in tests so far to see if SQL would pick and use the best index based on what we were looking up data on. The good news is that it did a fairly decent job of picking an index and returning the data in a fairly short amount of time. This approach, where we are specifying a WHERE with as much info as we have, seems to work just fine if we don't know of or have a specific index we want to lookup against.
ReadCustIdx - We fetched records on DataAreaId, CustAccount, SalesId and PurchOrderFormNum. This was our best performing lookup by index and reviewing the features of the index, it makes sense. This index, CustIdx, has CustAccount, SalesId and PurchOrderFormNum all together as a unique index. In terms of how SQL is looking at data it will do a "soft filter" based on CustAccount first then lookup SalesId then PurchOrderFormNum from that initial "soft filtered" list so it just ends up being faster because it uses parts of the WHERE to get rid of just to scan prior to doing any additional scans.
TL;DR - Key Takeaways
- Indexing Matters so pay attention and use them
- If a specific index isn't known, specify everything you can and let SQL pick an index for you
- The better the index selection for a query, the faster the query is as well as being more reliable from a performance perspective
All data and Power BI visuals can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest/tree/main/Projects/AAXDataEntityPerfTest/Part5/Analytics
All code can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest
Minor Pre-publish Update
I was able to secure a UAT environment with Contoso data so I could run the same tests as above just to compare them. The visuals and data have been added to the repo.
Fetching 1 Record - UAT
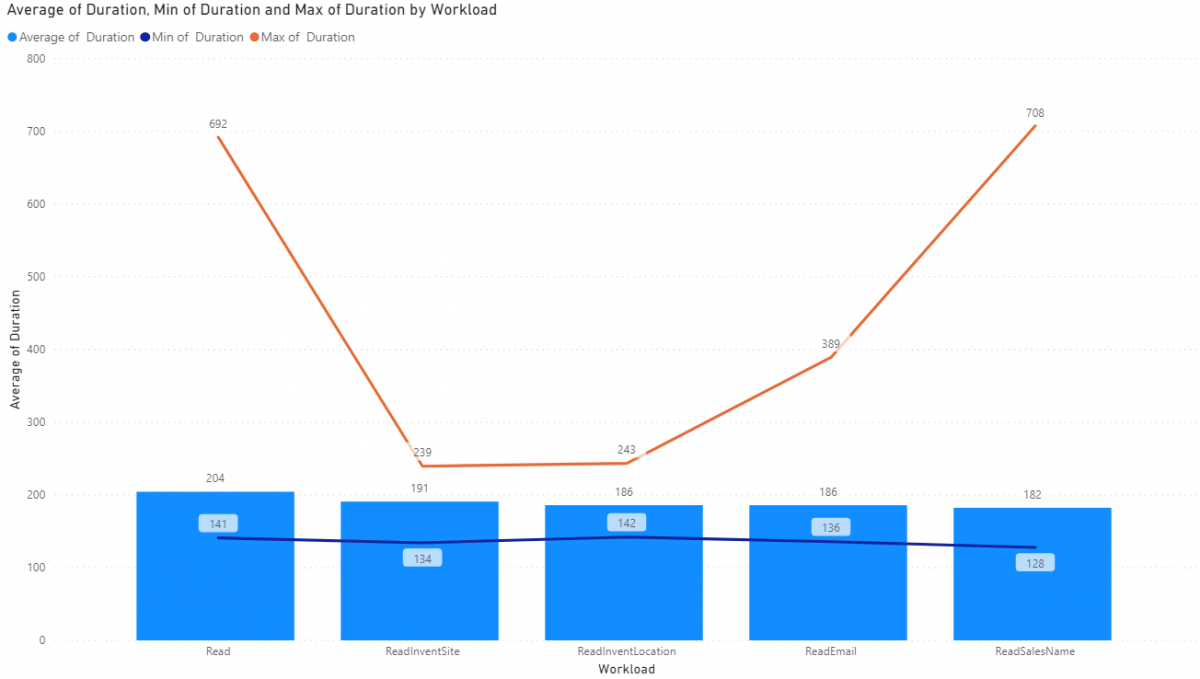
Overall better than a development environment but you can see we have increased overall variability due to network between the F&O instance an the consumer plus the database for Tier 2 and above have a small distance between the app and db that development environments don't have.
Fetching 10 Records - UAT
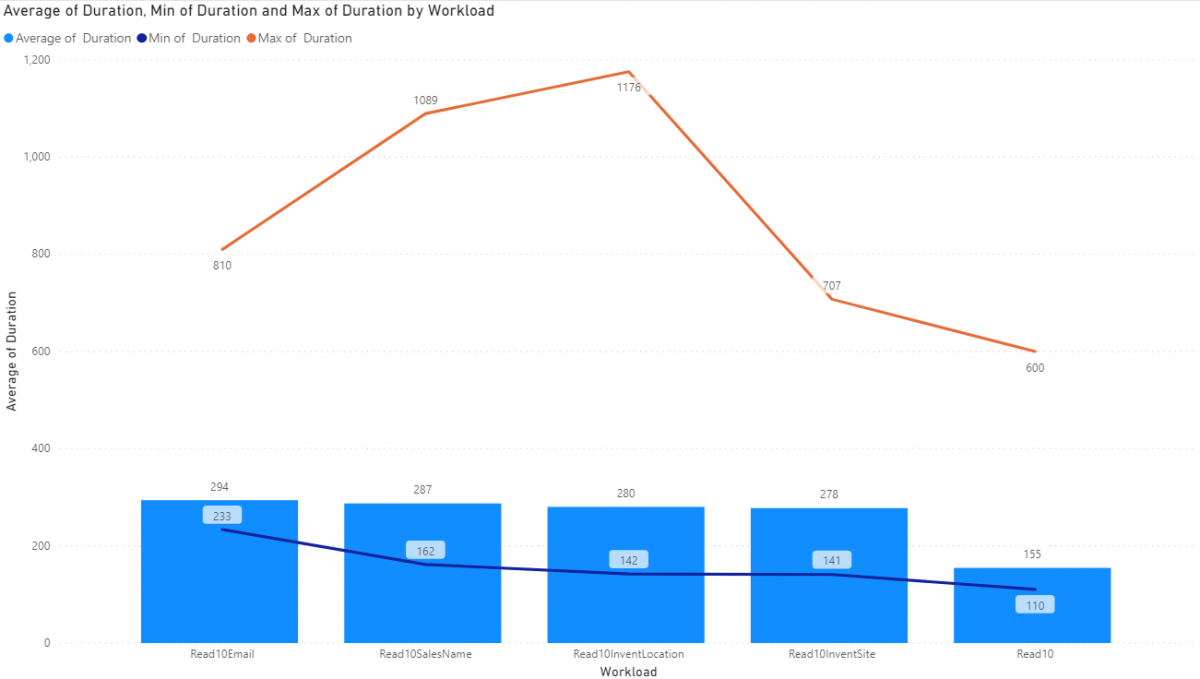
Some mixed results; some better, some worse.
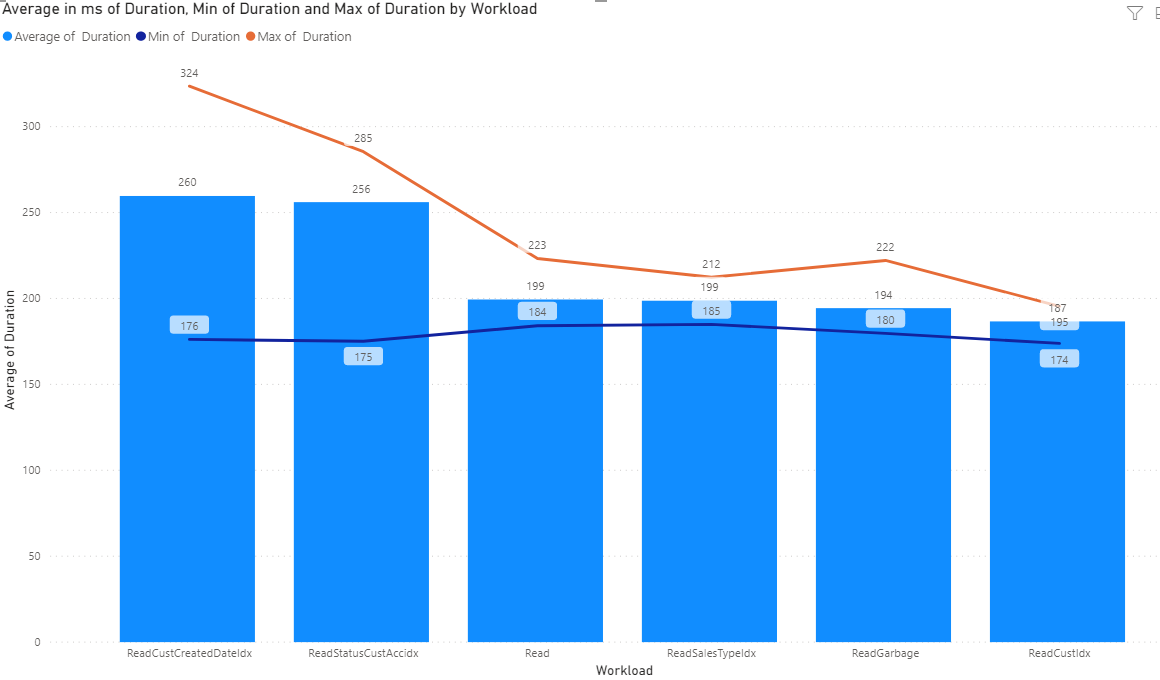
Fetching 1 Record By Specific Indexes
Overall better than a dev environment but again, increased variability potential.
Blog Main Tag:











