

Let's simplify publishing new NuGet packages for x++ builds
Database Inserts - Code Table
Does the process of inserting data with Code matter for performance?
When inserting data in F&O, there are several best practices on how to do this from MSFT. But for this specific type of workload, do those best practices really matter? Can I code up a solution that is less than ideal and still have a workable solution? Let's find out. This will only look at Azure hosted VM performance for the time being.
Firstly, as a refresher, we'll be reviewing the basic workloads outlined here: https://www.atomicax.com/article/database-inserts-and-performance.
The Results
Single Insert
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#Single...
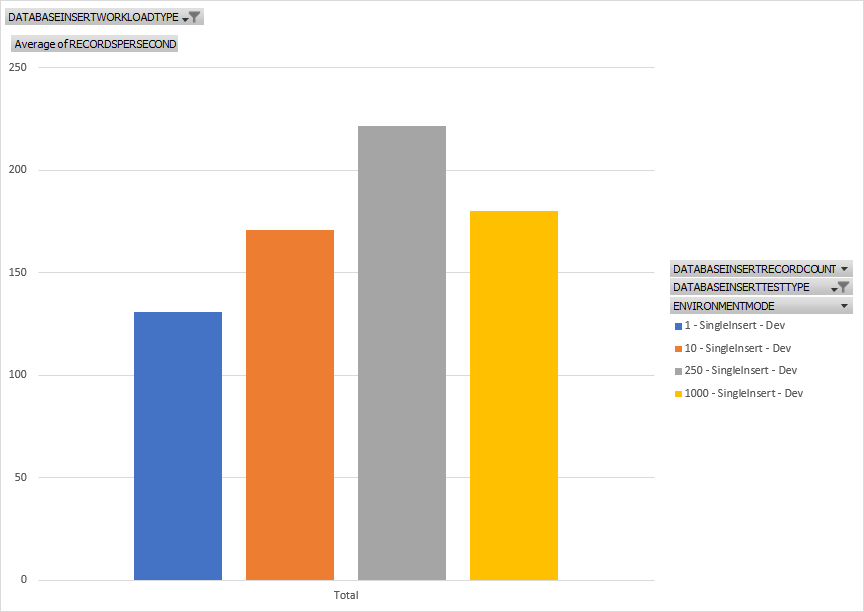
So what are we looking at? when using a single insert pattern with test size of 1, 10, 250, and 1000, we're looking at the average of the calculated records per second based on the amount of time to insert x records from start to finish for the test. What we can see is that the overall throughput for this method goes up over time, generally, for the given number of records inserted. in short, inserting 1 record gets us the slowest throughput when looking at all records inserted per second.
Multiple Insert
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#MultiI....
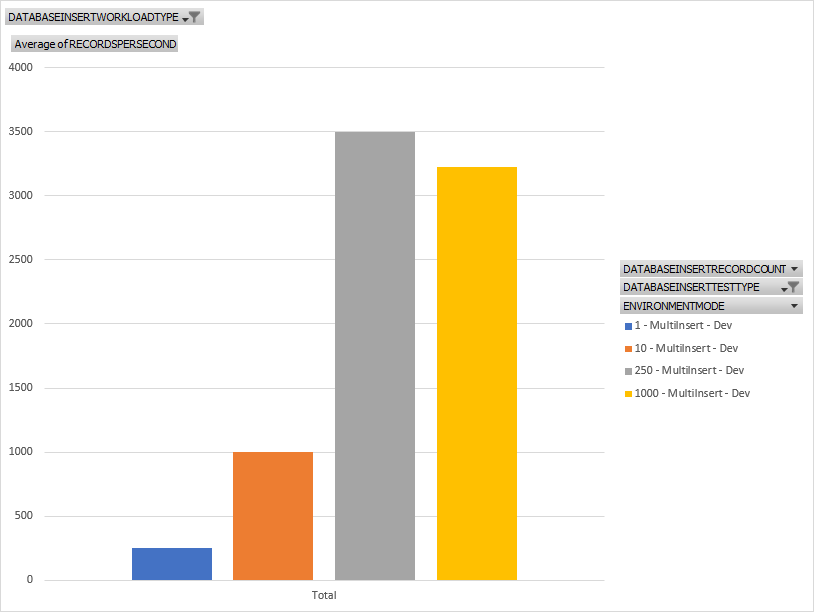
Same as the last test but we're looking at a pattern where we open a transaction, insert lots of records then close the transaction. You can see is much faster for nearly all test sizes. So always do this rather than doing a single insert - create a transaction for each insert that is. You can also see that for larger insert sets, we get much more throughput.
Insert_RecordSet
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#Insert....
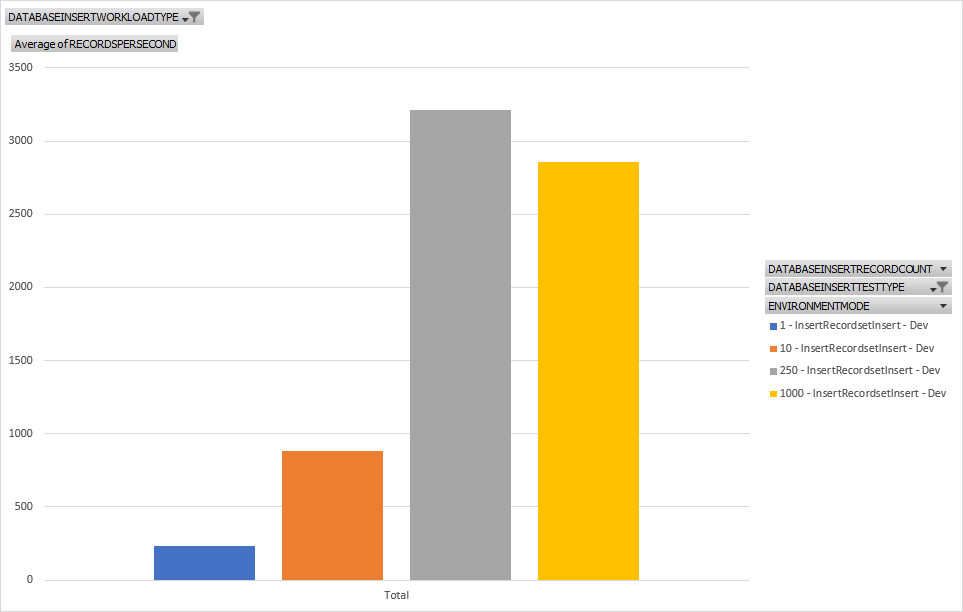
Similar with the last test but using an Insert_Recordset construct. Again we're seeing overall better performance for nearly all test sizes. We don't have quite the peak performance numbers that the multiple insert pattern does but still much better than a single insert pattern.
Query Insert_RecordSet
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#QueryI....
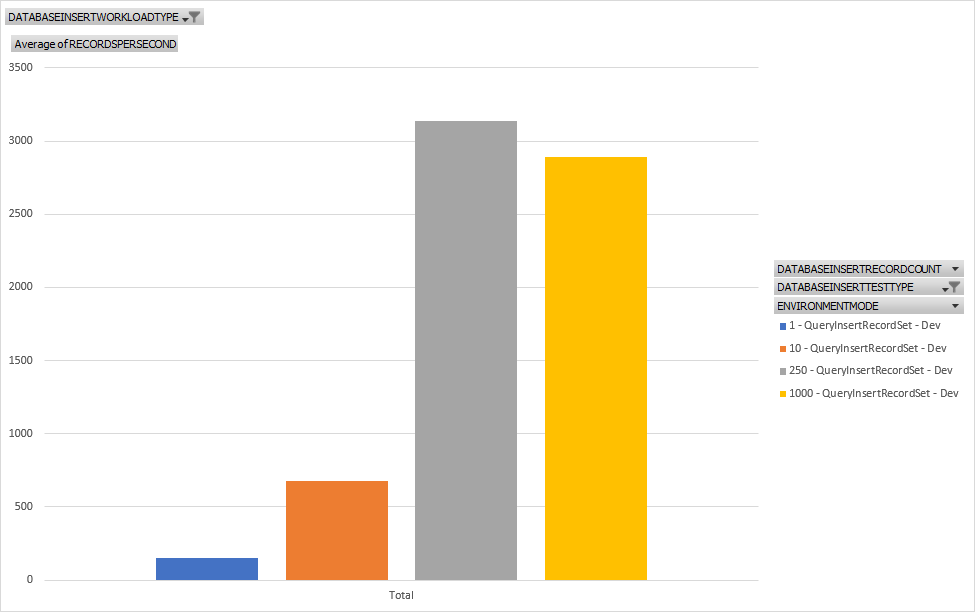
This is a nearly identical to the Insert_RecortSet test but we're using a query based Insert_RecordSet Operator. The performance is nearly identical so I wonder if it is executing the same kernel code behind the scenes.
RecordInsertList
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#Record....
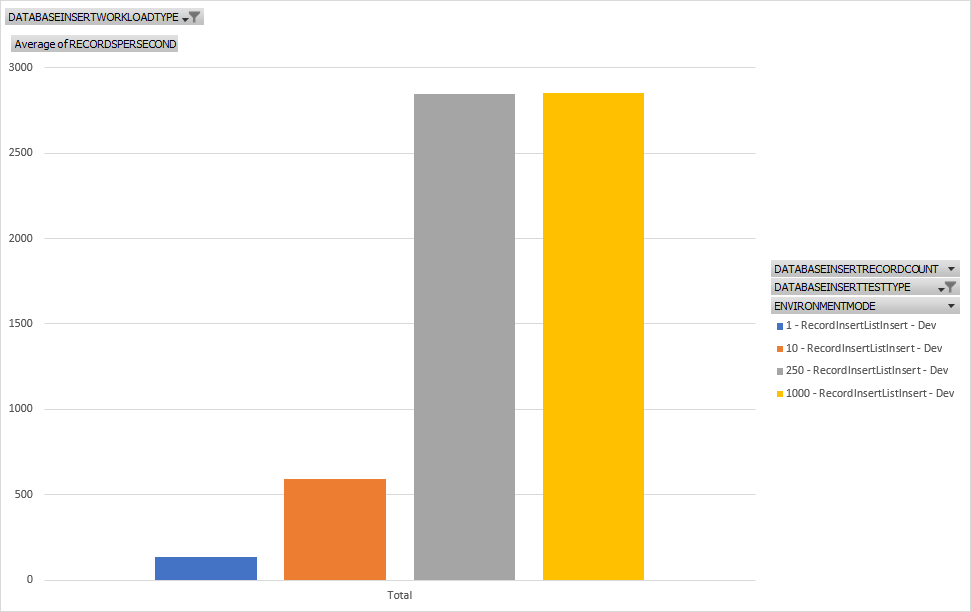
Here we're using a RecordInsertList and we're getting the expected results. The larger the set, the faster it is. It also doesn't exhibit any slowdown for larger sets of inserts showing this pattern is best for this type of workload for throughput.
RecordSortedList
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#Record....
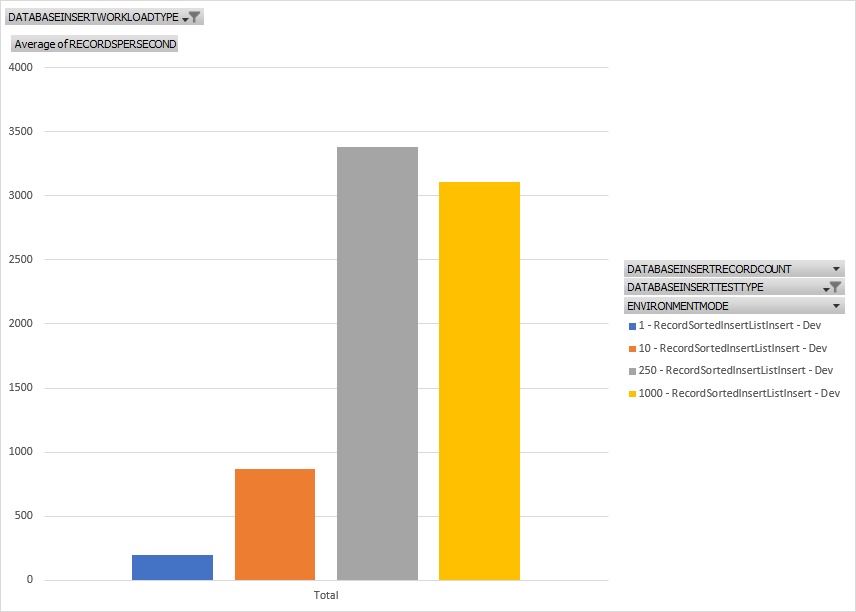
This is very similar to a RecordInsertList. Here we're seeing better performance numbers than a RecordInsertList. I suspect this is because the overhead you would typically have with a sorted list isn't incurred in our case because the data is presorted outside of when we're capturing statistics for the test. Still, a good option for inserting large amounts of data.
SysDAInsertObject Insert
The basic test used here is available at https://www.atomicax.com/article/database-inserts-and-performance#SysDAI...
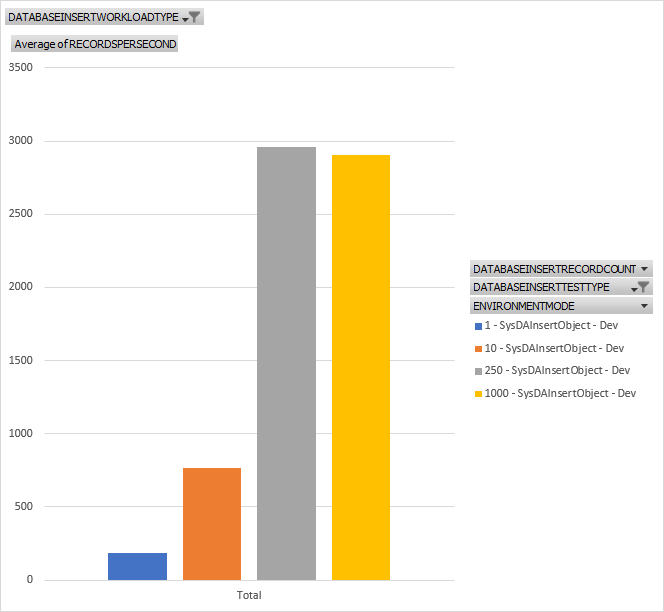
Here we're using a much newer insert option of SysDAInsertObject. You can read more about SysDA at https://learn.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/dev.... Here we see good numbers but still not as good as either the RecordInsertList or RecordSortedList. Also, its important to note how the newer SysDA classes are used and what they can and cannot do.
Conclusions
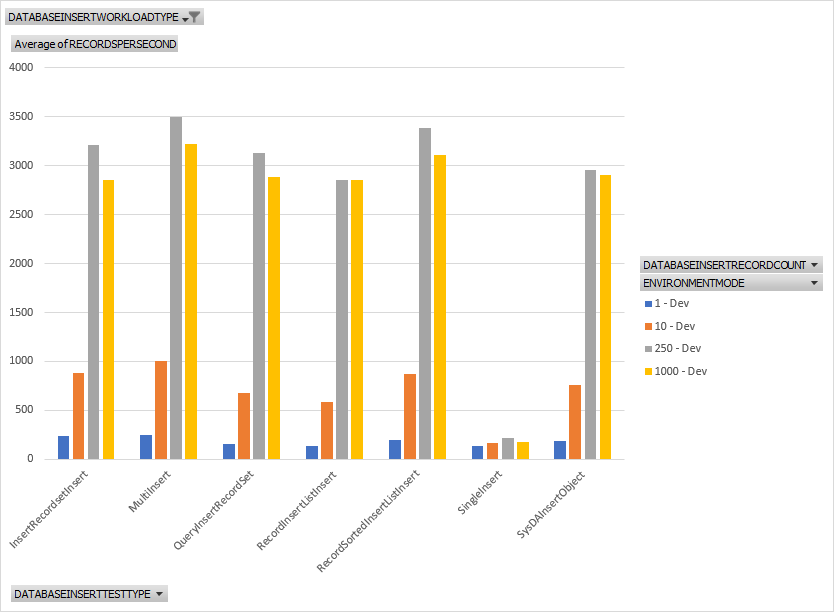
Above is a chart for all workloads for all sizes. We don't have any real clear winner in all categories. For 10 records, we get some very close numbers for throughput. The same can be said for 250 and 1000 showing that there is some overhead in opening and committing a transaction but just piping tons of data in can be fast in sets. We do have a clear loser in all workloads though. The Single Insert pattern performs the worst for all insert sizes. Event modifying the Single Insert pattern to be a multi insert pattern for 1 record gets us a minor performance gain. Click on the chart below to see how poor the Single Insert pattern performs specifically against all other workloads.






