

Creating an XDS Policy with performance in mind
Part 3 - Getting Data, Faster
Now that we can get data, let's look at getting data faster.
Out of the box Finance and Operations delivers thousands of entities many of which are enabled for OData consumption. These are good for standard integrations but can be slow depending on what it is you are trying to do. Also, most of these entities are non-specialized. That is to say they handle all CRUD operations. But, can create read only versions and/or slimmed down versions of entities to get data much faster? Too Long, Didn't Read at the bottom.
The Setup
We have several entities with several differences setup to test their overall read performance. We will be testing 2 scenarios: a random read and as well as a repetitive read. A random read will come from a random value of a known list of items we can lookup preloaded into the testing programs code. A repetitive read will be 1 random value used over and over. This will help us determine what is a constant level of execution time from the application and what variability comes from SQL (or a semi random workload in general). We will be using the following entities. Some are available out of the box and some are custom. To review the code for this, please see https://github.com/NathanClouseAX/AAXDataEntityPerfTest. This article uses the Part3 project for the data collection and the X++ project for the data entities.
Sales order headers V2 (Public Name SalesOrderHeaderV2) - Standard entity out of the box
Sales order headers V2 readonly with the delivery address (Public Name SalesOrderHeaderV2ExistAddrReadOnly) - Another standard out of the boxentity
Sales Order Headers - Test - Entity Read Only (Public Name SalesOrderHeaderV2EntityReadOnly) - This is a copy of the standard entity with the entire entity set to read only
Sales Order Headers - Test - No Globalization (Public Name SalesOrderHeaderV2EntityReadOnlyNoGlobalization) - This is a copy of the standard entity that is read only but also all data sources that were related to globalization have been removed such as SalesTable_W, SalesTable_BR, and BaseDocument_IT
Sales Order Headers - Test - SalesTable Only (Public NameSalesOrderHeaderV2EntityOnlySalesTable) - This is a copy of the standard entity with all data sources that weren't table SalesTable removed
Sales Order Headers - Test - DS Read Only (Public Name SalesOrderHeaderV2EntityDSReadOnly) - This is a copy of the standards entity with all data sources marked as being read only
AAX Sales Table (Public Name AAXSalesTable) - This is an entity built on top of table SalesTable only but it supports all CRUD operations but doesn't have any code in the entity
AAX Sales Table - Read Only (Public Name AAXSalesTableReadOnly) - This is an entity built on top of table SalesTable as a read only entity.
The Job
We're interested in what gives us the fastest result. It stands to reason the the most simple entity will deliver data the fastest and that's a true assumption. However, not all workloads are created equal, handled equally and scale in a way that you may expect. So we'll be testing the follow:
Random Single Reads - As noted above we will want to look at reads for a single expected record. We will be pulling a Sales Order Number and Data Area ID pair randomly from a declared list from known Contoso data.
Repetitive Single Reads - we'll also want to look at read performance when a client is given the same criteria. We will using the same Sales Order Number and Data Area ID to request data from an entity repeatedly.
Random Reads for 10 Records - We'll also see how packaging and scaling changes performance times. We'll be pulling a set of 10 records based on Customer Accounts with more than 10 Sales Orders associated with them in a given Data Area ID.
Repetitive Reads for 10 Records - Similar to above, we'll be checking how packaging and scaling changes when asking for the same data over and over.
The Rundown
We'll be testing this on 2 environment types. They will be an environment image (Local VHD) and Tier 1 in Azure. Each environment will be running the same set of tests but the set of inputs for the test will be unique for each test run. Because of differences between datasets the environments, we won't have exactly 1 to 1 to 1 for comparison purposes but we'll be fairly close. The only differences will be fairly minor as all will be the result of manual manipulation of data (adding new orders, customers or similar). However, we should be able to tease our some trends and themes. If I'm able to gather data from a UAT environment, I'll update this article to include that data.
The Results
Local VHD
Let's review the results from the Local VHD. The Local VHD represents our "best case". All resources are local, there is no "over the wire" lag to consider, there is no chance of hardware contention and the hardware on the host is fairly good (AMD 3900X, 2 M2 drives, 128G RAM). First, single reads by entity reviewing the average duration for 100 tests. All results are in milliseconds (ms).
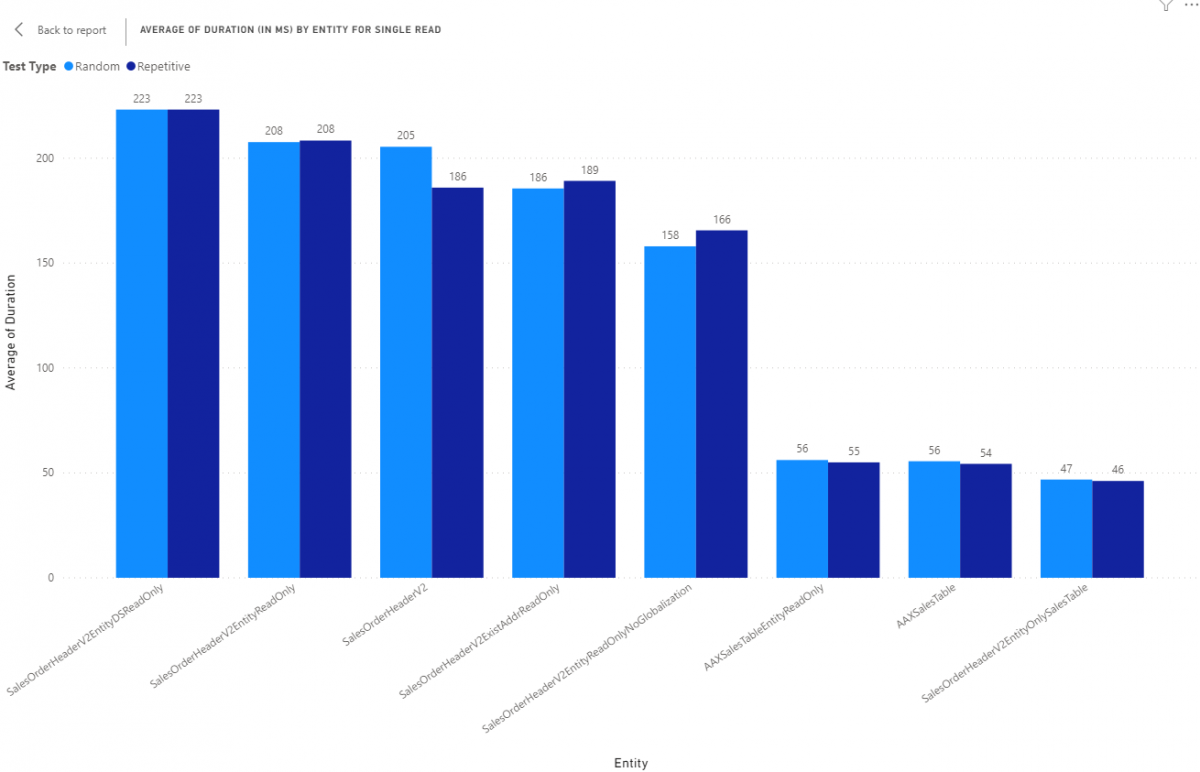
From left to right, we are looking at average times going down as the overall complexity of the entity goes down. AAXSalestableEntityReadOnly, AAXSalestable and SalesOrderHeaderV2EntityOnlySalesTable have no joins and contain only 1 table so these represent the most simple way to present data. Also, take note that AAXSalesTableEntityReadOnly and AAXSalesTable have more columns in the result than SalesOrderHeaderV2EntityOnlySalesTable so columns should also be considered when evaluating the overall complexity of an entity and its relative performance.
Next, let's review reading 10 records from the same set of entities with the same test types. All results are in milliseconds (ms).
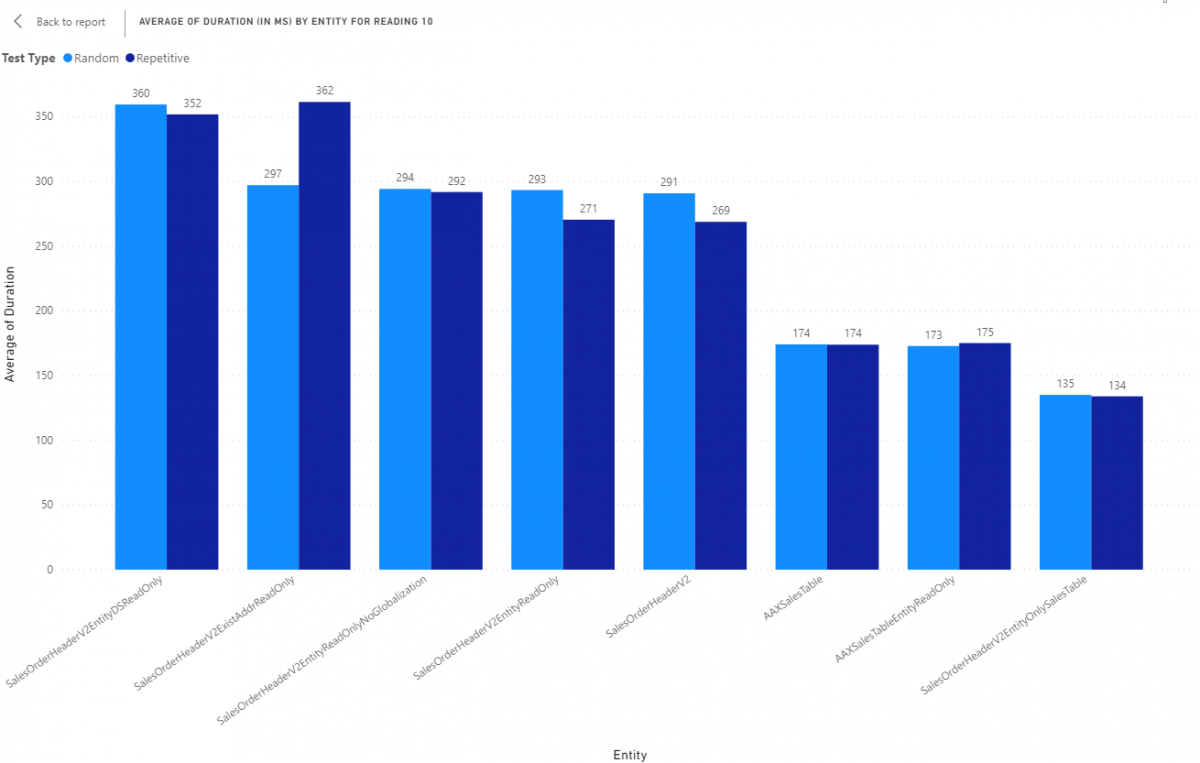
Again, from left to right, we are looking at average times going down as the overall complexity of an the entity goes down. However, We don't see such a huge difference from our simple entities compared to our more complex entities. We can also see that number of datasources in our entity as well as the number of columns plays into how the average times present and how the data wrapping scale. Simply, more columns means more work per row and that manifests when working with more than 1 record.
Next, let's review how packaging and scaling of records looks.All results are in milliseconds (ms).
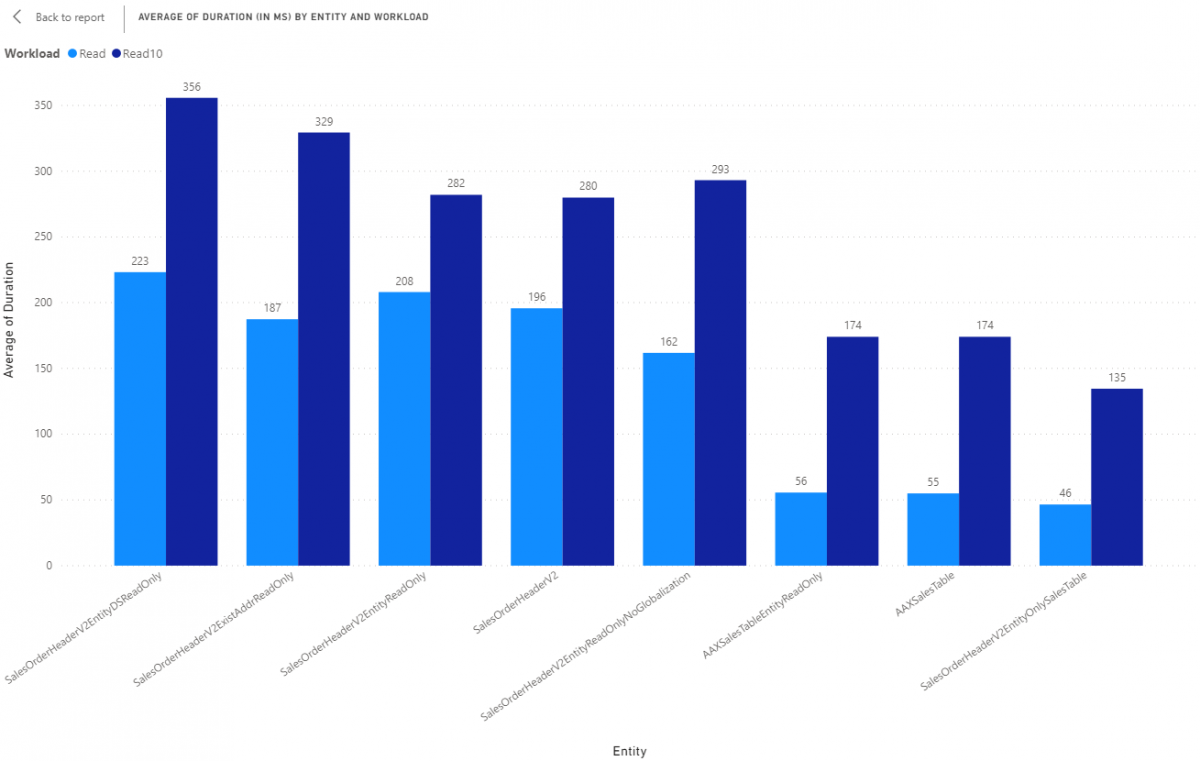
Again, we can see less complexity means "more faster". With the side by side comparison, we can see how what kind of overhead is incurred for 1 record vs 10 records. Using AAXSalesTable as an example, it on average takes 55 ms to get 1 record but 135 to get 10. We can see there is some overhead in those figures that is constant, like creating the data set, but also that the putting all the data into that dataset also increases time.
Tier 1 Environment
A Tier 1 Dev environment is similar to the local VHD but its in the cloud so this is more just to review the differences in performance so you can gauge if you need to further refine a data entity for a high performance scenario. Let's review single reads by entity reviewing the average duration for 100 tests. All results are in milliseconds (ms).
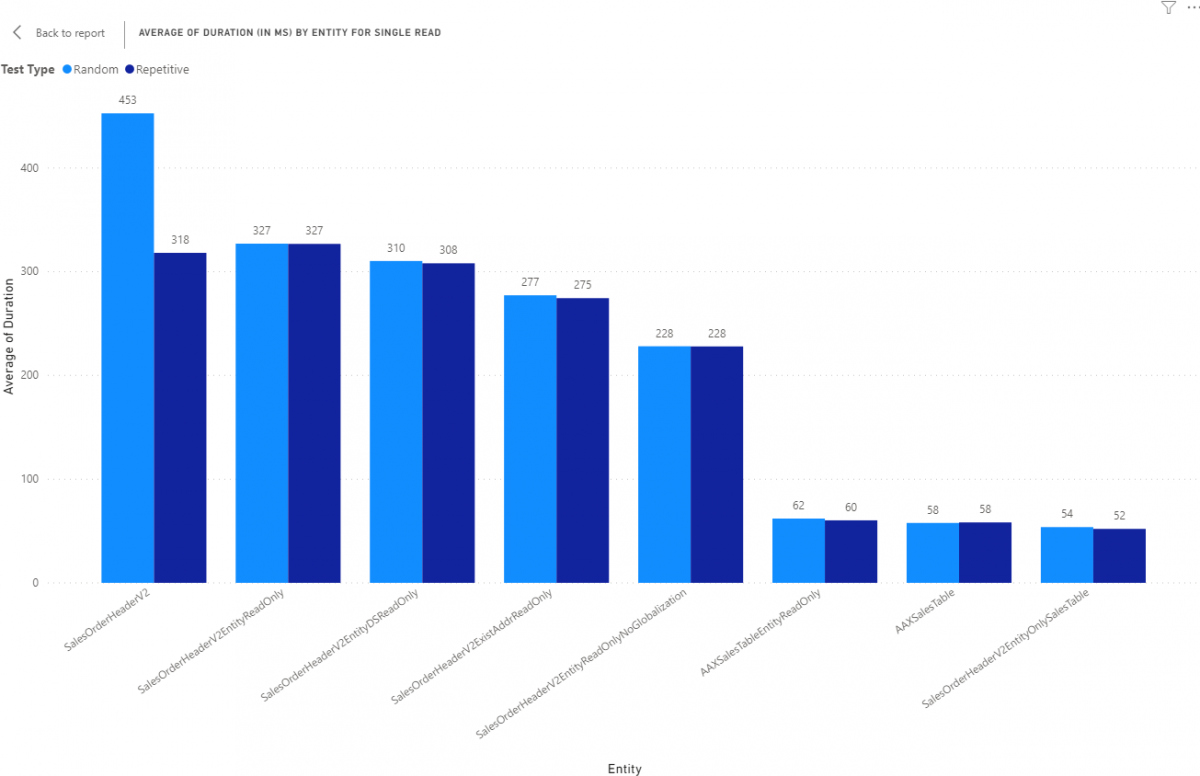
Similar to the VHD, just longer times on average.
Next, let's review reading 10 records from the same set of entities with the same test types. All results are in milliseconds (ms).
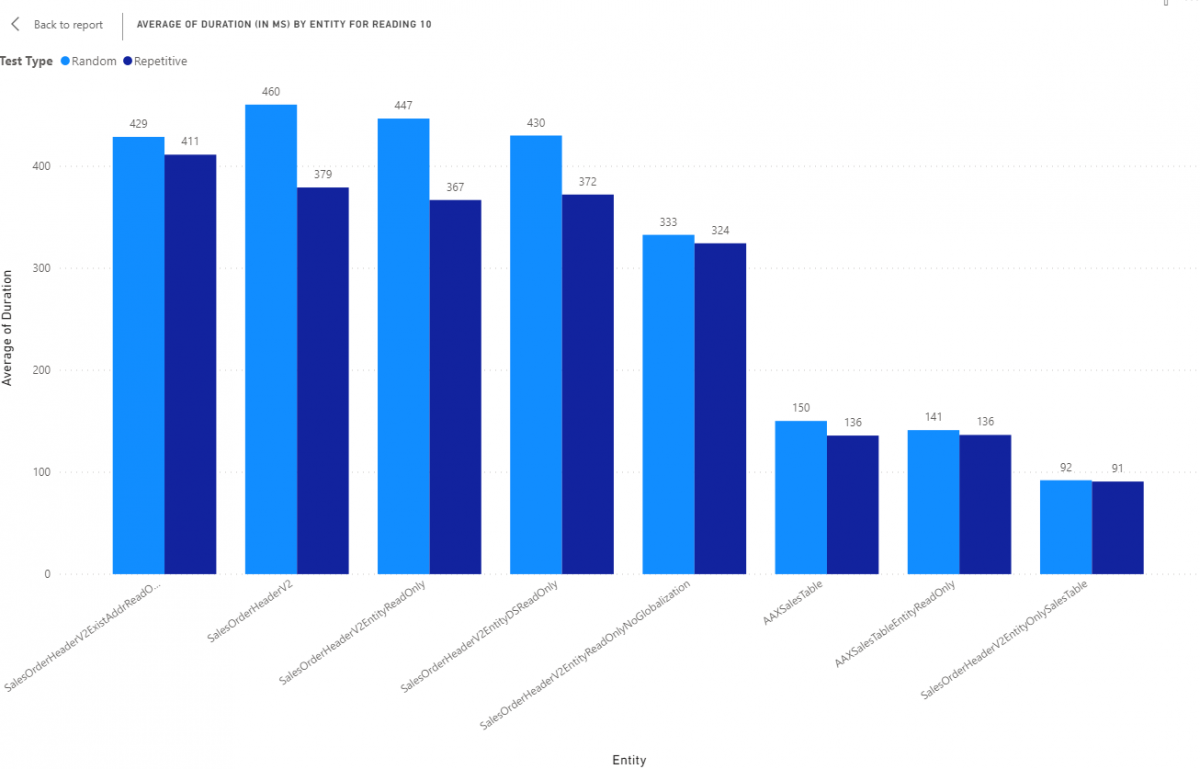
No real surprises but it does look like repetitive queries do fair better as compared to random. Probably do to slower storage and that manifesting on the random side as increased execution time.
Next, let's review how packaging and scaling of records looks. All results are in milliseconds (ms).
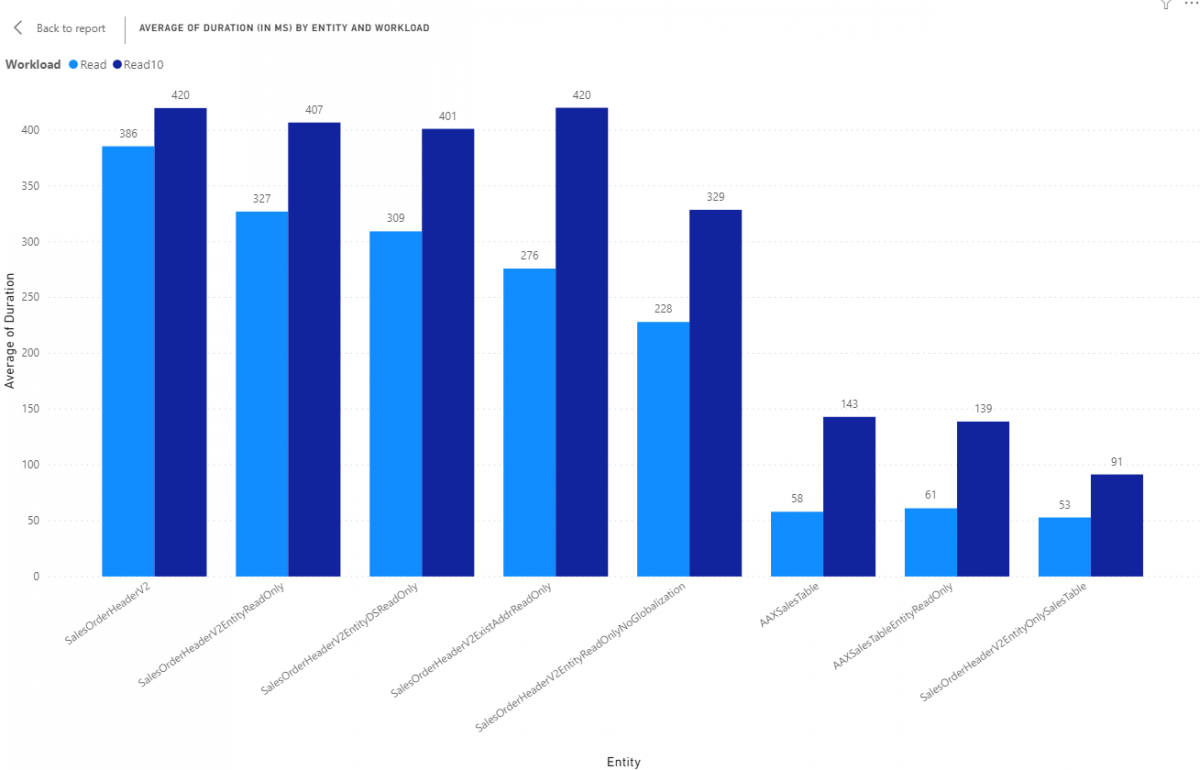
We have some increased variability here but overall, it looks like for reading more than 1 record, a tier 1 environment overall does better. This is more than likely a combination of slow storage increasing the single read time as well as CPUs with higher clocks. 1 core at 3.8ghz is faster than at 2.8ghz for sheer computational speed (which is what we need for throughput).
TL;DR - Key Takeaways
- Fewer Columns = more faster
- Fewer table / joins = more faster
- ReadOnly attribute is for functionality, not performance
- More faster for 1 row means more faster for 10+ rows
All data and Power BI visuals can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest/tree/main/Projec...
All code can be found here: https://github.com/NathanClouseAX/AAXDataEntityPerfTest
Blog Main Tag:











